MonoAvatar builds a 3D avatar representation of a person using just a single short monocular RGB video (e.g., 1-2 minutes).
We leverage a 3DMM to track the user's expressions, and generate a volumetric photorealistic 3D avatar that can be rendered with
user-defined expression and viewpoint.
Input Driving Video Rendered Avatar Rendered Depth
Input Driving Video Rendered Avatar Rendered Depth
Abstract
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The
learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid
pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained
control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict
local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D
space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network
in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments
show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization
to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.
Overview
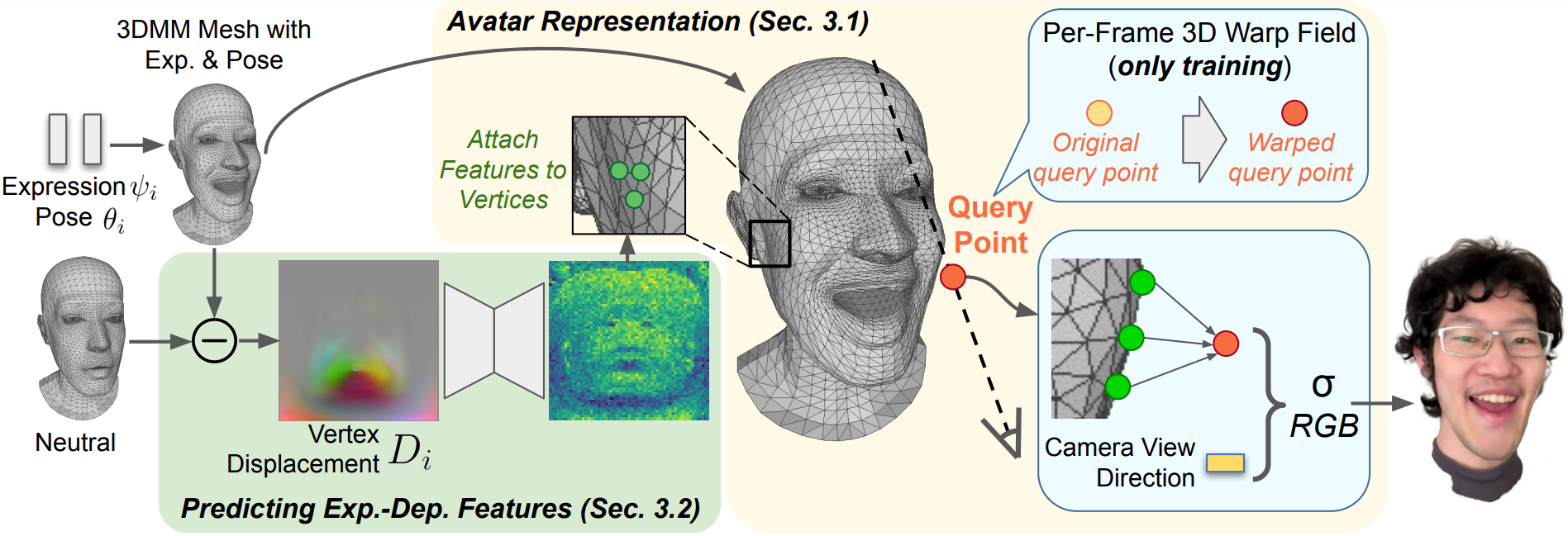
Overview of our pipeline. The core of our method is the Avatar Representation (Sec.3.1. Shown as the yellow area) based on a
3DMM-anchored neural radiance field (NeRF), which are decoded from local features attached on the 3DMM vertices. Then, we use
volumetric rendering to compute the output image. To predict the vertex-attached features (Sec.3.2. Shown as the green area),
we first compute the vertex displacements from the 3DMM expression and pose, then process the displacements in UV space with
Convolutional Neural Networks (CNNs), and sample the obtained features back to mesh vertices.
Results of driving the avatars by an unseen test video sequence of the subject
Our learned avatar produces high-quality renderings and geometries, and captures personalized
characteristics such as winkles:
Our method can also handle fluffy hairs and accessories like glasses:
Our method generates reasonable results for challenging long hairs. For more discussions,
please refer to the limitation section at the end of the page.
Furthermore, our method can also reproduce personalized complex expressions.
Results of comparing to state-of-the-art 3D avatars
Labels - From left to right: (1) Input Driving Video, (2) Ours,
(3) NerFACE [1], (4) NHA [2], (5) IMAvatar [3]
More Results of Multi-view Rendering
Labels - From left to right: (1) Input Driving Video, (2) -15 degrees,
(3) 0 degree, (4) +15 degrees
Results driven under different capturing conditions
After training, the learned avatar model can be driven by the same subject under different
capturing conditions, such as differences in hair styles, illumination, and glasses.
Nevertheless, our method still has limitations. Our results degrade when rendering from side
views with large angles, which is partially due to missing data for the back of the head.
Limitations when rendering long hairs
Also, our method has difficulties on handling long hairs with complex deformations, which
cannot be captured by the 3DMM.
Limitations when rendering glasses deformed by 3DMM with refraction
Finally, the deformation on 3DMM surface may incorrectly warp rigid accessories like
glasses. Also, current method does not model refraction effects, which are overfitted by
incorrect appearances.
References
[1] Guy Gafni, Justus Thies, Michael Zollhofer, and Matthias Nießner.
Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction.
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[2] Philip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother,
Matthias Nießner, and Justus Thies. Neural Head Avatars From Monocular RGB Videos.
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
[3] Yufeng Zheng, Victoria Fernandez Abrevaya, Marcel C. Buhler, Xu Chen,
Michael J. Black, and Otmar Hilliges. Imavatar: Implicit morphable head avatars from
videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition (CVPR), 2022.