MonoAvatar++ builds a 3D avatar representation of a person that can be rendered in real-time, from just a single short monocular RGB video (e.g., 1-2 minutes).
We leverage a 3DMM to track the user's expressions, and construct an efficient volumetric 3D avatar that can be rendered in >= 30 FPS with 512 x 512
resolutions, given user-defined expression and viewpoint.
Input Driving Video Rendered Avatar Rendered Depth
Input Driving Video Rendered Avatar Rendered Depth
Abstract
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism.
However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly
in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural
rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions,
such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit
head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality.
Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an
underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting
in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight
MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach
runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
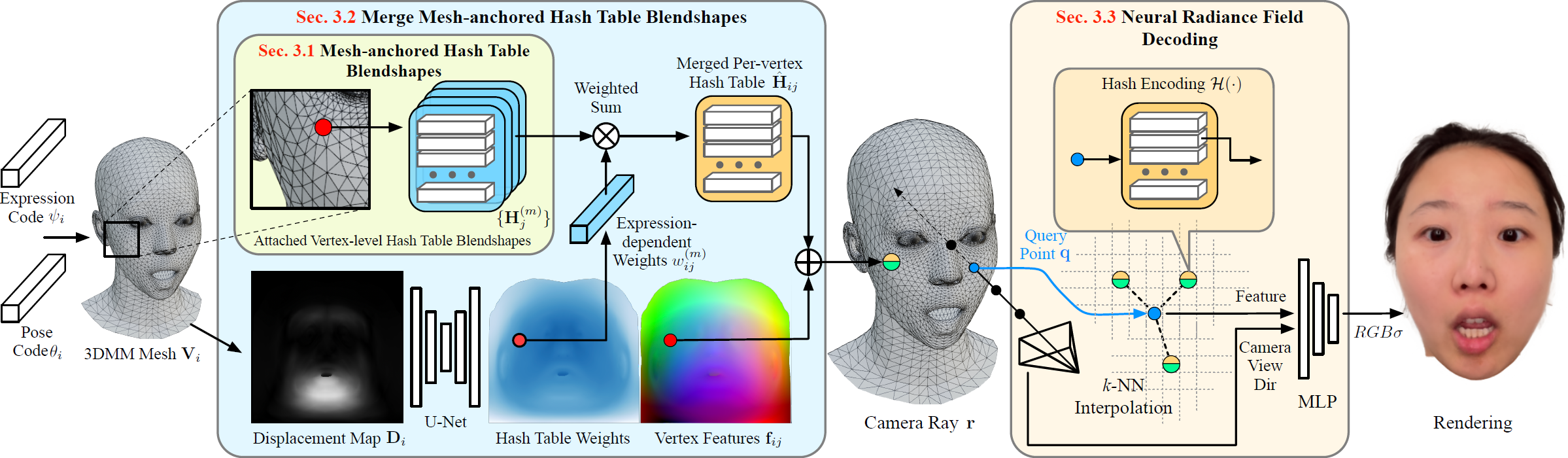
Overview
Overview of our pipeline. Our core avatar representation is Mesh-anchored Hash Table Blendshapes (Sec.3.1), where multiple
small hash tables are attached to each 3DMM vertex. During inference, our method starts from a displacement map encoding
the facial expression, which is then fed into a U-Net to predict hash table weights and per-vertex features. The predicted
weights are used to linearly combine the multiple hash tables attached on each 3DMM vertex (Sec.3.2). During volumetric
rendering (Sec.3.3), for each query point, we search its k-nearest-neighbor vertices, then pull embeddings from the merged
hash tables and concatenate with the per-vertex feature to decode local density and color via a tiny MLP with two hidden layers.
Results of comparing with the state-of-the-art approaches.
Compare with PointAvatar[1], INSTA[2],
NeRFBlendshape[3], MonoAvatar[4].
Our method is able to achieve one of the best rendering quality while maintaining real-time rendering speed.
We build a real-time demo based on our method, where we track the facial performance of the actor with a webcam, and
render our avatar on a workstation with a RTX3080Ti. Finally, we display the rendered stereo pair on a headset and a
webpage. The tracking results and rendered videos are streaming through the internet, which may cause latency between
the driving and the rendering, and slightly unsmoothed videos.
References
[1] Yufeng Zheng, Wang Yifan, Gordon Wetzstein, Michael J Black, and Otmar Hilliges.
Pointavatar: Deformable point based head avatars from videos. In CVPR, 2023. [link] [2] Wojciech Zielonka, Timo Bolkart, and Justus Thies.
Instant volumetric head avatars. In CVPR, 2023. [link] [3] Xuan Gao, Chenglai Zhong, Jun Xiang, Yang Hong, Yudong Guo, and Juyong Zhang.
Reconstructing personalized semantic facial nerf models from monocular video. In SIGGRAPH Asia, 2022. [link] [4] Ziqian Bai, Feitong Tan, Zeng Huang, Kripasindhu Sarkar, Danhang Tang, Di Qiu, Abhimitra Meka,
Ruofei Du, Ming song Dou, Sergio Orts-Escolano, et al.
Learning personalized high quality volumetric head avatars from monocular rgb videos. In CVPR, 2023. [link]